“Towards a model of urban evolution” is a series of papers that seeks to articulate a formal model of urban evolution. Part I provides context and background for the effort, situating it against related work across multiple fields and arguing that the evolutionary approach has the potential so synthesize them. Part II lays out the core terms and functions of the model. Part III shows how the model can be used to characterize urban evolution in terms of variation, selection, and retention.
The latest version of Part I was recently published on SocArXiv and can be accessed here. Below is the abstract.
Abstract: This paper seeks to develop the core concepts of a model of urban evolution. It proceeds in four major sections. First we review prior adumbrations of an evolutionary model in urban theory, not-ing their potential and their limitations. Second, we turn to the general sociocultural evolution litera-ture to draw inspiration for a fresh and more complete application of evolutionary theory to the study of urban life. Third, building upon this background, we outline the main elements of our proposed model, with special attention to elaborating the value of its key conceptual innovation, the “formeme.” Last, we conclude with a discussion of what types of research commitments the overall approach does or does not imply, and point toward the more formal elaboration of the model that we undertake in “Towards a Model of Urban Evolution II” and “Towards a Model of Urban Evo-lution III.”
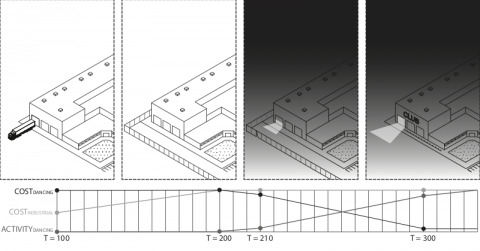
A challenging part of developing evolutionary models of cities is their dynamism. We must find ways to treat change rather than static states as our topic of interest. That is, we often want to understand what something is by how it becomes. Two neighbourhoods might be very similar in terms of their characteristics right now, but have very different propensities to change. Likewise, two neighbourhoods might be quite different at the present moment, but change in similar ways. However, standard methods have a hard time identifying these sorts of similarities grounded in shared propensities to change in response to varying conditions.
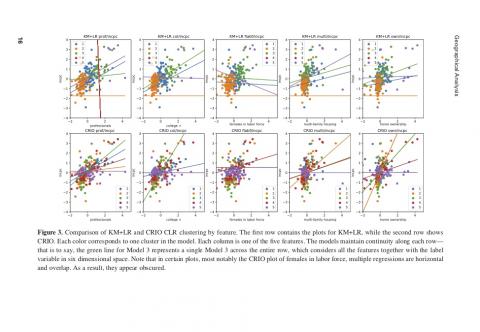
• Conceptually, predictive clustering is highly distinct from traditional methods—in particu-lar, LR. Because it relies on a predictive model, it can uncover how specific characteristics influence an outcome researchers are interested in studying. We can then observe heteroge-neity in those influences and use it to cluster observations. This perspective makes neigh-borhood dynamics fundamental to the definition of urban space.
• Methodologically, in contrast to traditional neighborhood classifications, predictive cluster-ing is based on a specific outcome to which areas similarly “respond.” In other words, our proposal can be considered model-based clustering (Fraley and Raftery 2002). This frame-work defines the current state of a neighborhood as a set of variables thought to influence trajectories of change. In this article, following a long tradition of research, we use income change to illustrate the potential of this methodological feature of our approach (for a recent example, see Hochstenbach and Van Gent 2015).
• Practically, predictive clustering has clear implications that differentiate it from the tradi-tional K-Means approach. Our approach can identify neighborhoods that exhibit different processes of change even if they look similar at any given point in time, and similar dynam-ics even when they look different. Not only is this potentially useful for urban policymakers when designing interventions, it cannot be readily examined when one only considers char-acteristics of the neighborhood, as in the traditional K-Means approach.
Below is the abstract, and here is a link to the paper.
Abstract:
This article applies a method we term “predictive clustering” to cluster neighborhoods. Much of the literature in this direction is based on groupings built using intrinsic characteristics of each observation. Our approach departs from this framework by delineating clusters based on how the neighborhood’s features respond to a particular outcome of interest (e.g., income change). To do so, we leverage a classification and regression via integer optimization (CRIO) method that groups neighborhoods according to their predictive characteristics and consistently outperforms traditional clustering methods along several metrics. The CRIO methodology contributes a novel methodological and conceptual capability to the literature on neighborhood dynamics that can provide useful insights for policymaking.