Our paper “Mapping Policy Pathways: Urban Referencing Networks in Public Art Policies” has been published in Urban Studies. This study grows out of a line of collaborative research on the topic of policy mobility (Keidar & Silver, 2022, 2023). Policy ideas — like the Percent for Public Art, the focus of our study — travel from city to city, and as they do, local actors adapt and revise them to their own context, while learning and comparing themselves to other cities.
While a large and thriving literature on policy mobility in geography focuses on local case studies, and quantitative research in political science focuses on the narrow question of whether a policy is adopted or not, our approach offers distinct methodological advantages. Our work draws on a large corpus of public art policy documents of all the largest cities in the Anglophone world (N=26) since 1959. With a grounded approach, we focus on the local meaning of such policy ideas, and with quantitative methods, we uncover the broader patterns that shape the “space of ideas.”
In “Mapping Policy Pathways: Urban Referencing Networks in Public Art Policies” we study how policy actors in one city refer to other cities in their policy documents. Policy actors routinely look to other cities as reference points – as models, comparators, or more – when they formulate their own local policy ideas. “Mental maps” emerge, but they do not exist only in individuals’ heads: they are embedded in policy statements that create and recreate international inter-referencing networks. Our paper uncovers the structure of these patterns of referencing networks and examines their underlying structure, guided by two key questions:
What are the contours and attributes of the referencing network?
Who are the cities that emerge as prominent reference points, and why?
We built the reference network by identifying all instances of each city name in each document in our corpus. From this, we generate a network, in which two cities are connected if one city mentions the other. The strength of each connection is determined by how often one city mentions another.
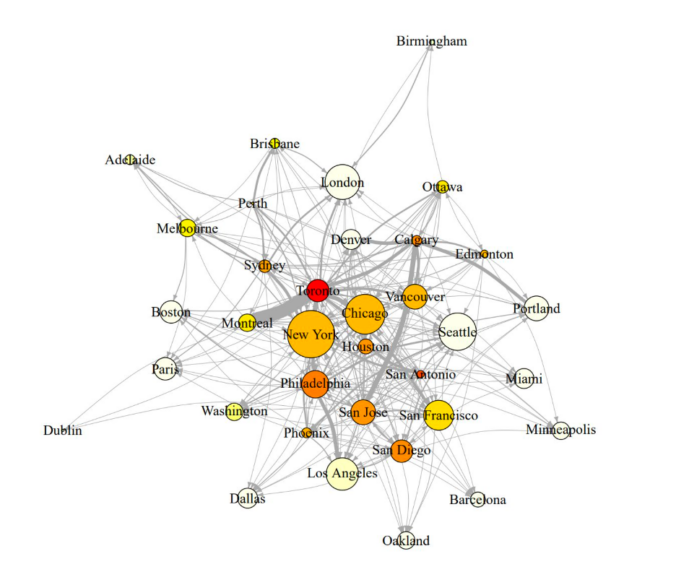
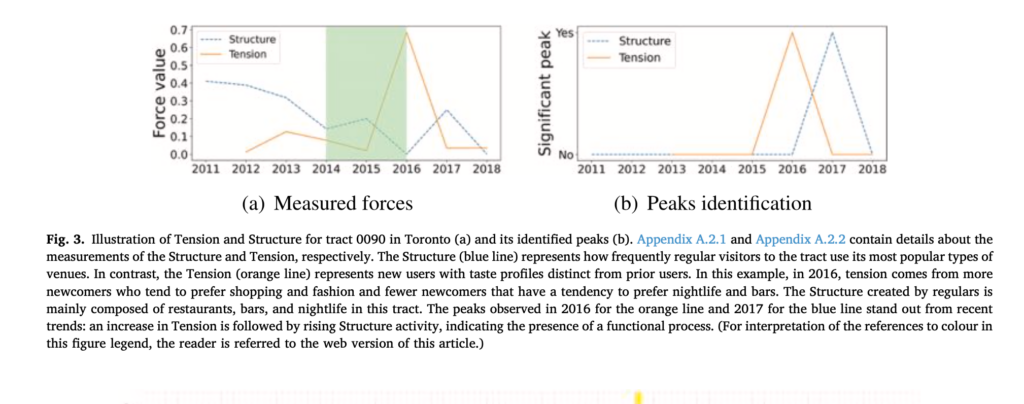
Figure 1 shows the central result:
Note: The plot depicts the public art referencing network for our complete corpus of policy documents over the entire period under study (1959-2020), with nodes representing cities and edges representing the direction and intensity of referencing. Node size is based on in-degree centrality scores representing how many mentions each city received, and node color is based on out-degree centrality, with darker shades indicating cities that refer to other cities at higher rates. Edge thickness is proportional to edge weight, with thicker lines representing more referencing from one city to the other.
The most central cities of the public art referencing network are cities like New York, London, and Los Angeles. These are examples of what Bunnell (2013) calls “pathway cities,” those positioned at the top of the global hierarchy of urbanity, illustrating developmental pathway for other cities to follow. Other central nodes illustrate “policy description” cities, which presents a model for a policy strategy that can urge an urban transformation. For example, Chicago and Seattle – both recognized as leaders in the public art policy domain — are very central in the inter-referencing network, even though they are lower on global urban hierarchies. Montreal illustrates another form of centrality – captured by authority scores – in which it is highly referenced by other highly referenced cities.
With further regression analyses, we examine how attributes of the referenced cities, as well as contextual characteristics of referencing cities, correlate with these both types of centrality – degree and authority. Overall, the features of referenced cities have a strong and significant effect, while the contextual characteristics of the referencing cities are less salient. Among the attributes of the referenced cities, their global economic importance and their iconicism (mentions in experts’ lists of iconic artworks) have the strongest positive effect on the degree of references, and a weaker effect on the authority score. The significance of these factors alludes to the gravity of being a “pathway city” (Bunnell, 2013).
The authority score, however, shows the importance of policy expertise. It is found to be highly correlated with early adoption cities, and with members in UNESCO’s Creative Networks. This urban referencing network approach could be applied to diverse policy domains, like climate change, affordable housing, or smart cities. By revealing the distinct network contours and central nodes it helps uncovering how cities become policy models.
References:
Bunnell T (2013) Antecedent Cities and Inter-referencing Effects: Learning from and Extending Beyond Critiques of Neoliberalisation. Urban Studies, 52(11): 1983-2000.
Keidar N and Silver D (2022) The space of ideas: Public art policy and the concept of urban model spaces. Journal of Urban Affairs: pp.1-24.
Keidar N and Silver D (2023). Urban policy assemblage: Outcomes and processes of public art policy assemblage. Cities,138(May), 104365.
Charlotte is a University of Toronto undergraduate, majoring in Biodiversity and Conservation Biology and Environmental Ethics, with a minor in Geographic Information Systems. Charlotte is working closely with Tyler Bateman, a PhD candidate in the Department of Sociology who specializes in Environmental Sociology.
Tyler leads a project studying the various factors that lead to a species becoming classified as invasive, and recently presented results at the Canadian Sociology Association meetings. The research asks two connected questions: 1) What are the cultural meanings of invasive species? and 2) Where do these cultural meanings come from? To answer these questions, the study pursues a computational analysis that uses government texts, biological species records, and additional social data to predict the meanings of individual non-native species— some of which are widely thought of as “invasive”, some of which are not.
The data comes from documents collected in Toronto, Ontario. The findings to date demonstrate a wide diversity in how non-native species gain their meanings. Some species, like the four species dubbed “Asian Carp,” do not have to be physically present to be discussed in policy, labelled invasive and to gain meanings associated with danger and peril. Yet many species, such as dog-strangling vine, do not gain the meaning as invasive for a long period following their establishment. In the paper, we discuss these and other variations in terms of how they relate to social factors. These findings help understand the ways cultural meanings subtly guide political and organizational decision-making.
This project was featured in the School of Cities Research Insights series on the Urban Genome project, available here.
This summer, Charlotte has been assisting Tyler to add new variables to the analytical model. Specifically, they classify each species’ position in the “invasion curve” (defined below) and ask how that classification impacts the species probability of being treated as invasive.
Usually, this sort of classification would be produced manually, and is quite laborious. We wondered if GPT-4 could speed up the process. If it could classify species accurately enough, this would not only tremendously reduce the amount of time and labor necessary to study this and similar phenomena, but it would also permit us to explore other variables that we would otherwise deem to costly or time consuming to incorporate.
Charlotte experimented with various prompts. As her post documents, results were not good enough for us to trust GPT-4 for this research purpose. While we did not explore all possibilities — results might improve for example if we supplied GPT-4 with a more detailed training process — for our present purposes we set it aside and returned to manual coding.
Nevertheless, we would be delighted to receive any recommendations for how to improve and get better results.
Reflections on OpenAI’s ChatGPT-4 for Classification of Invasive Species
Charlotte Kafka-Gibbons
Characterization of a particular species as invasive is a powerful rhetorical tool. Consensus that a non-native species is spreading and harming native ecosystems has the potential to catalyze action by conservation and natural management authorities. Nonetheless, definitions of the exact factors that make a species invasive are nebulous and conflicting.
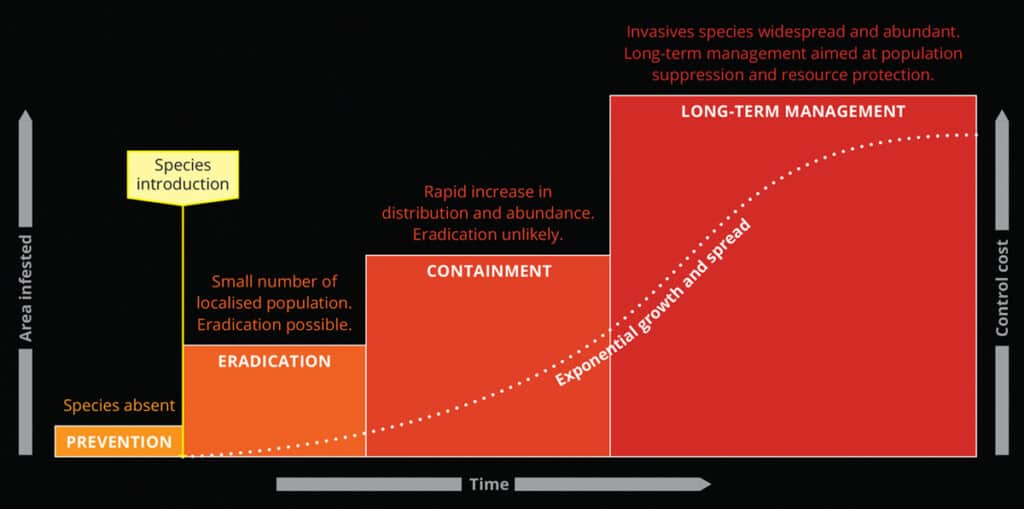
When considering the severity of invasion and most effective management strategies, the invasion curve is an important model. The Canadian Invasive Species Centre defines an invasion curve with four stages, each classifying a specific management strategy and when that strategy should be used based on the extent and impact of invasion (Invasive Species Centre, 2023). The first stage—prevention—represents the actions taken to reduce risk of introduction for known invaders that have not yet been introduced to a region. The second stage—eradication—represents management strategies that focus on complete removal of invaders that are in beginning stages of invasion. Next, the containment stage is reached when likelihood of complete eradication is low but there are sufficient un-invaded areas that can be effectively protected. Finally, the long-term control stage is reached when the species has spread widely throughout the region of focus, and resources are directed towards keeping populations low and reducing negative impacts.
When exploring the social factors of invasive species perception, knowing where a species falls on the invasion curve in the region of focus, in our case the Greater Toronto Area, can provide valuable context. For this reason, using government documents, we classified 70 species that the Toronto Region Conservation Authority (TRCA) describes as non-native into the four categories of the invasion curve. We experimented with using OpenAI’s ChatGPT-4 tool to aid in this classification but found it to be unsuccessful in its current model, in the end opting for manual classification. ChatGPT-4 is the most recently developed publicly available chatbot by OpenAI, accessible through paid subscription and more powerful than the free version of GPT. Specifically, we used the May 2023 version of GPT-4. We wanted to describe the process we followed in experimenting with GPT-4 as a data collection tool, to contribute to ongoing discussions of the utility of this novel tool.
To begin, we created a prompt with instructions for classification. The prompt specifies detailed definitions for the invasion stages, the set of species to classify, and instructions to run 5 independent duplicate classifications for each species—identifying the consensus result. The prompt also describes formatting for output results, guidelines on justifying classifications, and guidelines on citing sources used.
Initial Test Prompt:
You are an expert ecologist and sociologist, with expertise about the ecology of the Toronto, Ontario area. You are studying the process by which some organisms become classified as invasive or not. You have a hunch that it has to do with the position of each species on what is known as the “invasion curve.” The invasion curve shows the stages of invasive species management from pre-arrival (prevention) to long-term control. After a species is introduced, management costs increase, and likelihood of eradication decreases as time passes. Prevention: The most cost-effective solution for managing invasive species. Public awareness is essential for this stage. Eradication: Removing a species population in its entirety. If populations are localized, eradication is possible. Containment: Reducing further spread of an introduced species. As populations increase, eradication becomes increasingly unlikely, and priorities shift to preventing further spread. Long-term control: The most costly stage of invasive species management. Eradication is unlikely to impossible, and we instead focus on limiting populations and protecting remaining resources. I would like to give you a set of species. Please generate a table, classifying each one’s position on the invasion curve. The table should include the species’ name, the classification on the invasion curve, a brief explanation of why you classified the species that way, and citations to sources to justify the classification. I would like you to repeat this classification 5 times for each species. Forget the prior classification between each attempt, in other words, each time you reclassify the same species, it should be independent. The table should therefore include 5 rows for each species, showing how you classified each species in each independent run. Then add an additional column, which is an indicator variable to show which of the 5 classifications was the consensus. Whichever received the majority should have a 1, the others a 0. Here are three species to try to classify: Asian Long-Horned Beetle, Garlic Mustard, Purple Loosestrife.
This prompt utilized invasion curve definitions from the Canadian Invasive Species Centre, but revised prompts used definitions from Leslie Anthony’s book The aliens among us: How invasive species are transforming the planet–and ourselves (Anthony, 2017; Invasive Species Centre, 2023). In a test-run of this prompt with three species, GPT provided data in response and produced a disclaimer that the results may be insufficient, prefacing the data table with the statement:
For this exercise, I’ll make some simplifications based on the information available. If this was a real research project, a more detailed and context-specific analysis would be necessary.
(OpenAI, 2023)
GPT also emphasized that the data could only be informed by sources up to 2021. Nonetheless, GPT-4 produced a table with classifications, explanations, sources, and replicates. Below is the output for Garlic Mustard:
Species
Classification
Explanation
Citation
Consensus
Garlic Mustard
Long-term control
This species is well-established in Toronto, making long-term control the primary strategy.
Second, I then scaled up to using the full set of 70 species. I also classified the species manually to check the classifications from GPT-4. After revising the prompt to include all 70 species, GPT rejected the outlined instructions within the prompt, stating:
I’m sorry for the confusion but due to the complexity of the task and the character limit for responses, it’s not possible to generate a comprehensive table for 70 species within this format.
(OpenAI, 2023)
The full set of 70 species could not be generated with GPT-4’s current limitations. I decided to break the prompt into 7 separate prompts, identical besides having different sets of 10 species. GPT was able to produce a table in these 7 runs but rejected prompting to independently analyze each species 5 times and use the consensus of these duplicates. Another significant issue is that some species had no source cited at all. The table below is a selection of GPT-4’s output, showing one species with a broken source link and one with no source documented:
Species
Classification
Explanation
Citation
Oncorhynchus mykiss (Rainbow Trout)
Long-term Control
The species has established populations, and management efforts are focused on control.
Can be invasive in North America and efforts are often made to control its spread.
–
(OpenAI, 2023)
Comparing with the manual classification, 28% of invasion curve classifications matched those done manually. GPT-4 overwhelmingly classified species either in the prevention or long-term control categories, with very few in eradication or containment. The species that were consistent between the GPT-4 and manual classifications were overwhelmingly those in the long-term control category. This could be due to greater documentation and discussion of species with higher range and abundance. Many species that GPT-4 categorized in long-term control were manually classified in eradication or containment, suggesting that the more ambiguous intermediate stages on the curve are more challenging to identify with artificial intelligence. The manual classification involved synthesizing multiple factors for each species: current/past conservation efforts, abundance, range, biotic interactions, and ecological impacts. Consideration of these factors may allow for a more comprehensive categorization.
In attempts to revise this prompt, the 70 species were broken down into 14 sets of 5. This was the run of the prompt. GPT-4 successfully produced an output with 3 independent classifications for each species. However, only 35% of the cited links were functional, and of those that worked many were for an incorrect species or relied on US conservation authorities, while the prompt specified focus on TRCA jurisdiction. By rewording the prompt and adding greater detail, the number of classifications matching the manual dataset grew from 28% to 46%. However, this match rate is still too low to suggest that GPT-4 can perform with equivalent success to manual classification.
Overall, it was valuable to investigate what ChatGPT-4 is able to accomplish when it comes to loosely-defined socio-biological factors. GPT-4 does a remarkable job producing coherent and convincing analysis at first glance. However, when checked against official sources, accuracy was not high enough to be used for our purpose. Manual classification seemed the most efficient and effective protocol for this project. Nonetheless, ChatGPT is being constantly updated and its power as a research tool is steadily improving. With further research, continued prompt development, and usage of other tools such as ChatGPT plug-ins, we might be able to see a higher level of success in replicating the manual classification process.
References
Anthony, L. (2017). The aliens among us: How invasive species are transforming the planet–and ourselves. Yale University Press.
Investing in Prevention: Invasion Curve. (n.d.). Invasive Species Centre. Retrieved August 3, 2023, from https://www.invasivespeciescentre.ca/learn/invasion-curve/
OpenAI. (2023) ChatGPT-4 (May 2023 Version) [Large Language Model].
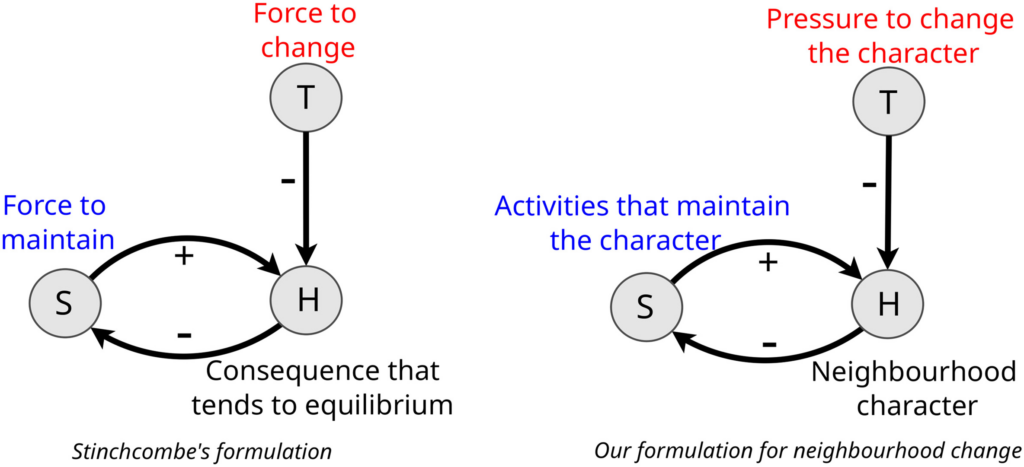
One key way that evolutionary processes occur is via feedback loops. A classic way to model such feedback loops is in functional terms. Arthur Stinchcombe articulated the elemental structure of functional explanations in his 1968 book, Constructing Social Theories. In our recently published article, “Complex causal structures of neighbourhood change,” we try to revive this model and demonstrate its value for studying the evolution of cities.
The above figures shows Stinchcombe’s model on the left, and our reformulation of the model for neighbourhood evolution. It codified the causal structure of a complete functional explanation in terms of four core elements:
The consequence that tends to be maintained, which also functions indirectly as a cause of the behaviour or social arrangement to be explained. This is H, the “Homeostatic” variable. Though H may tend to be stable empirically, its stability is maintained against pressures to change it, such as in the case of body temperature.
The social arrangement or behaviour that impacts H, the explanandum. This is S, the “Structure.” In a functional model, Structures tend to maintain Homeostasis. For example, sweat glands tend to maintain body temperature.
Tensions that tend to upset Homeostasis, unless Structures maintain it. This is T, the “tension” variable. If physical activity or air temperature did not alter body temperature, there would likely be no structure to counteract the tensions they create.
Processes that reinforce or select for the S’s (structures) that maintain H (homeostasis). When H is threatened or pressured, these forces increase the activity of S when T (tensions) are higher and decrease when H is maintained. For example, sweat glands generate more sweat (S) when body temperature (H) is not maintained at normal levels due to a certain phenomenon (T). Since this structure helps to maintain H in equilibrium, it will tend to be selected or reinforced.
Stinchcombe’s diagram may be intuitively mapped onto familiar neighbourhood dynamics. For example, we may treat as Homeostatic (H) variables neighbourhood character, style, or scene (such as distinctive shops, restaurants, venues, or groups), Tension (T) variables as pressures to change that character (from, for example, new groups with divergent tastes), and Structure (S) variables as activities that maintain that character (such as Business Improvement Association sponsored festivals, political advocacy, or increased participation in venues and activities distinctive to that scene).
Based on this simple representation, we formulate an initial set of propositions regarding the presence and strength of 1) a functional relationship and 2) a homeostatic response, which can be seen in the paper in more detail.
The key value of such models from the point of considering urban evolution is that treat both persistence and change as a dynamic process. Urban forms of life are retained when there exist structures that preserve them when new challenges. If such structures respond effectively to tensions, there is a tendency for them to be selected and reinforced over time, generating both a pattern of structural retention and possible evolutionary histories of such structures. This idea is scarred further in Part III of “Towards a Model of Urban Evolution,” in our discussion of “retention hypotheses.”
Using data drawn from Yelp.com, we find considerable evidence that the sort of functional process envisaged in the model is a common feature of urban evolution. And in the process we develop novel methods for using data from Yelp and similar sources for such analyses.
We see great potential for using these models and methods for characterizing neighbourhoods in new ways. In contrast to the typical approach, which does so primarily by their demographics or built form, our proposed functionalist approach would identify neighbourhoods with more or less latent potential to resist tensions. In this way, neighbourhoods that look otherwise similar could be shown to have very different probabilities of maintaining their identity over time, thereby allowing planners and policymakers to take these latent functional capacities into account.
While incorporating novel data sources and methods would, to some extent, be challenging, doing so would be in line with parallel proposals. Indeed, local jurisdictions routinely use big data in multiple ways: traffic demand management (using GPS and sensor data), land use (using remotely sensed data), public health (COVID sewage testing), commercial health (using payments data), and more. Our methods could be used in a similar way to monitor tendencies toward neighbourhood change.
From the point of view of social science research more generally, perhaps the biggest result of our study is the possibility of reviving interest in functional explanation. While functional explanation has been characterized as “what any science does,” it has largely fallen out of favour in social science. We review common criticisms, and show that they do not apply to a properly specific functional model of the sort we propose.
At the same time, we find considerable evidence that functionalist motifs are commonplace in neighborhood change research. Researchers typically appeal to functionalist motifs when they discuss for example the capacity of local groups to push back against tensions or challenges as a key mechanism producing continuity or change. However, we found no examples in the neighbourhood change literature where an author who utilized a functionalist motif articulated the motif in an explanatory model that would render it testable. Instead, much neighbourhood change research remains largely descriptive, mapping types and directions of change across a range of variables.
We hope one result of our study is to illustrate a path for remedying this situation, which in turn would help to more formally incorporate evolutionary thinking into urban research.
A central theoretical goal of the Urban Genome Project has been to articulate a model of urban evolution. We develop the model in four papers, recently published together in Urban Science. The paper series is called “Towards a Model of Urban Evolution,” because its central task is to elaborate a rich yet rigorous formal language capable of formulating propositions about the evolution of cities.
Paper I is “Context.”It proceeds in four major sections. First, we review prior adumbrations of an evolutionary model in urban theory, noting their potential and their limitations. Examples include Chicago School Ecology, stage theories, and theories of cities as complex adaptive systems. Second, we turn to the general sociocultural evolution literature to draw inspiration for a fresh and more complete application of evolutionary theory to the study of urban life. Third, building upon this background, we outline the main elements of our proposed model, with special attention to elaborating the value of its key conceptual innovation, the “formeme”. A formeme is a specific encoding of urban space as a combination of physical features and the groups and activities toward which they are oriented.
In turn we discuss the value of the model, highlighting its extension of the basic inferential logic of population genetics and evolutionary ecology into the urban domain, including the goal of replacing essentialist with distributional thinking, group and development thinking with tree and network ideas. Last, we conclude with a discussion of what types of research commitments the overall approach does or does not imply. Among other things, we note that an evolutionary model of the sort we develop is neither reductive nor deterministic, nor is it necessarily progressivist or teleological. We conclude by suggesting that an evolutionary approach suggests embracing new metaphors for the role of the planner: the planner less as an engineer pulling the levers of a well-tuned machine and more as a gardener in a forest, seeking to cultivate a rich ecosystem while remaining sensitive to processes unfolding through their own dynamics.
Type of Dependence
Summary
Example
Principles Related to Form Features
Scope
Formemes with wider niches will tend to attract more resources. Formemes with wider niche width will have a relativity higher probability of survival when the environment is changing, specialized forms will be favored under stable conditions
McDonalds has a wider niche width than a vegan, organic hamburger stand.McDonalds is more likely to survive a 30% increase in the local minimum wage or a pandemic than the local hamburger stand.
Content
The viability of a formeme will be influenced by its proximity to groups with a preference for or against the substantive content of its activities or the group affiliation it affirms.
Ethnic shops will tend to proliferate in areas where members of that ethnicity reside; satanic book stores will have low survival rates nearby Evangelical Christian populations.
Distance
Propagation of a formeme depends on how physically close it is to other iterations of the same formeme.
The franchise of a successful operation will be more viable at some ideal physical distance from the original
Principles related to environmental features
Density
Propagation of a formeme depends on density of competitors in the environment
Neopolitan pizza thrives when there is a glut of pizza restaurants
Frequency
Propagation of a formeme depends on the size of the formeme’s population
The 28,000th Starbucks location propagates at a different rate and in different places than the first.
Principles Governing the Evolution of Urban Form
Paper II elaborates the formal model. It defines the Signature of an urban space, comprised of the information encoded in that space. This information consists of: an urban genome, which captures ideas regarding the groups (i.e., users) and activities (i.e., uses) to which a space’s physical forms are oriented; ideas among human actors regarding who (users) and how (uses) to utilize the space and its forms; and the signals that are communicated within and among urban spaces. Central to the model is the notion of the formeme, which provides the building blocks for a Signature. Formemes are units of urban information regarding physical forms, groups, and activities, which may be encoded in physical artifacts, signals, or human actors, and circulate among them. We then show how various metrics can define an urban area based on its Signature, and that these metrics can be used to measure similarity of urban spaces. The Signature, and its underlying formemes capture the sources of variations in urban evolution.
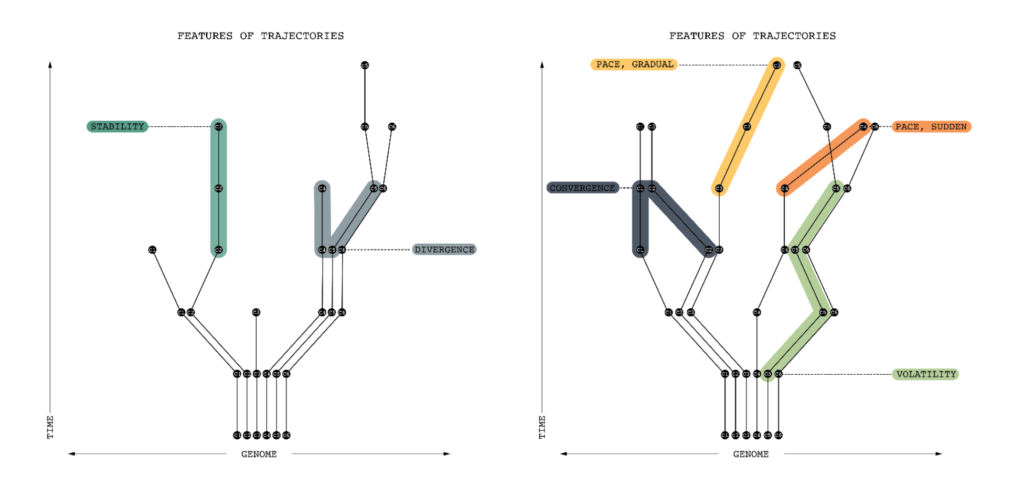
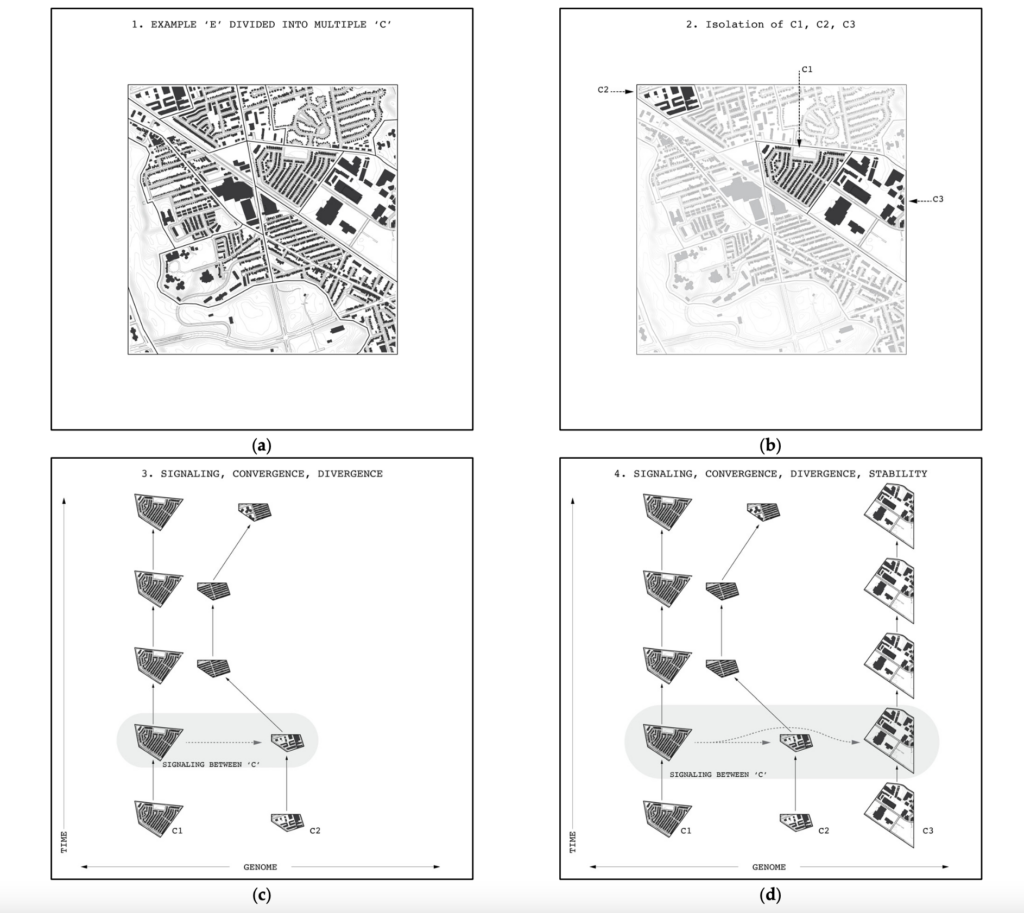
Paper III, “Rules of Evolution,” illustrates how to use the model to formulate propositions about urban evolution. It highlights (1) sources of variations; (2) principles of selection; and (3) mechanisms of retention. More specifically, regarding (1) it defines local and environmental sources of variation and identifies some of their generative processes, such as recombination, migration, mutation, extinction, and transcription errors. Regarding (2), it outlines a series of selection processes as part of an evolutionary ecology of urban forms, including density dependence, scope dependence, distance dependence, content dependence, and frequency dependence. Regarding (3), it characterizes retention as a combination of absorption and restriction of novel variants, defines mechanisms by which these can occur, including longevity, fidelity, and fecundity, and specifies how these processes issue in trajectories define by properties such as stability, pace, convergence, and divergence.
Paper IV, “Evolutionary (Formetic) Distance” provides an application of the model, using data from Yelp.com. It demonstrates how the Toronto Urban Evolution Model (TUEM) can be used to encode city data, illuminate key features, showing how formetic distance can be used to discover how spatial areas change over time, and identify similar spatial areas within and between cities. In this application, each Yelp review can be interpreted as a formeme where the category of the business is a form, the reviewer is a group, and the review is an activity. Yelp data from neighbourhoods in both Toronto and Montreal are encoded in this way. A method for aggregating reviewers into groups with multiple members is introduced. Specifically, we use the Apriori algorithm to aggregate reviewers by the types of venues they visit. Performing group aggregation using a level-wise search, this algorithm abstracts groups based on the forms they conducted reviewing activities for. Building on this basis, longitudinal analysis is performed for all Toronto neighbourhoods. Transversal analysis is performed between neighbourhoods within Toronto and between Toronto and Montreal. Similar neighbourhoods are identified validating formetic distance.
The Urban Genome Project at the School of Cities is hosting a talk next week by Bernie Koch on The Evolutionary Dynamics of Cultural Change (As Told Through the Birth and Brutal, Blackened Death of Metal Music).
This talk will be of special interest to those in the sociology of culture and computational social science, though it also has much broader import for general social theory and beyond . The talk will be on Thursday, February 3, 4:00 PM EST.
How does culture change? We unify disconnected explanations of change that focus either on individuals or on public culture under a theory of cultural evolution. By shifting our analytical lens from actors to public cultural ideas and objects, our theory can explain change in cultural forms over large and long frames of analysis using formal evolutionary mechanisms. Complementing this theory, the paper introduces a suite of novel methods to explain change in the historical trajectories of populations of cultural ideas/objects (e.g., music groups, hashtags, laws, technologies, and organizations) through diversification rates. We deploy our theory and methods to study the history of metal music over more than three decades, using a complete dataset of all bands active between 1968 and 2000. Over the course of its history, we find strong evidence that the genre has been fundamentally shaped by competition between ideas for the cognitive resources actors can invest in learning about and reproducing this cultural form over time.
Speaker Bio
Bernard Koch is a PhD candidate in the sociology department at UCLA. Inspired by pre-graduate work in evolutionary biology and bioinformatics, his research now uses computational approaches to examine cultural dynamics in fields as diverse as science and music. In his work on culture, he seeks to wed theories of cultural evolution and cognition with formal models of population change from biology. Other projects elucidate how the culture and organization of scientific fields (e.g., machine learning, IQ psychology) create ethical and epistemic challenges. Lastly, he has broad interests in Bayesian modeling, machine learning, networks, and causal inference. His research has been published at NeurIPS, WWW, Sociological Methodology, and Science, among other venues.
In Venues and segregation: A revised Schelling model we demonstrate that venues can play a crucial role in shaping urban evolution, in particular through influencing broader patterns of integration and segregation. Due to space considerations, we could not include a key study in the paper.
This study investigates whether and how venues can diversify a segregated city after it a particular segregation pattern has become deeply entrenched. To answer this question, we first simulate a highly segregated city as an outcome of a standard Schelling process. Then we use a genetic algorithm to evolve the set of rules that would most decrease the degree of segregation. These rules include the location of venues, their exclusivity, and their degree of obligatoriness. In effect, the study evolves rules that would most dramatically alter the evolutionary direction of a city.
The study is below. See the original paper for more details regarding the parameters and graphical conventions, and simulation rules.
Venues can unsettle sedimented patterns of segregation under certain conditions.
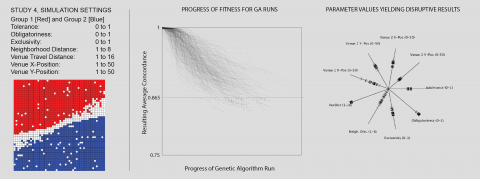
In this study, we demonstrate that the strategic placement of a new venue can unsettle sedimented patterns of segregation. This is important because one of the characteristics of the segregation patterns generated in Schelling simulations is that they are highly uni-directional processes. Once a set of individuals has become segregated, even a significant increase in their tolerance will not undo the neighbourhood divisions that have taken shape – barring any modifications to the internal psychology of individuals within the simulation. In this study, we show that venues can be used as an intervention within a settled Schelling model in order to disrupt the segregated outcome, without requiring any change to agents’ psychology. To do so, we add venues to a venue-less simulation that has already run its course and achieved a high level of segregated stability. In order to effectively determine what input parameters and venue positions will provide the most disruption, the two-dimensional parameter spaces used to explore earlier studies is not sufficient. Here we consider a range of venue positions, exclusivity, obligatoriness, tolerance, travel distance, and neighbourhood distance values simultaneously. In lieu of our prior interval based approach, we employ a Genetic Algorithm to test and recombine values for these parameters, evaluating different combinations in terms of how much they disrupt the initial condition (measured as a drop in concordance from the initial, segregated condition). An additional mechanism emerges, whereby one group’s venue establishes a “beachhead” into an area predominated by the other.
Figure 1 displays results. After running the algorithm with a variety of population sizes, mutation rates, and crossover rates, the progress of each evolutionary process is mapped as a sequence of fitness values to the chart in center of Fig 1. Here, movement towards the right along each thread indicates the progress of the algorithm during one of its runs, while dropping values on the Y-axis indicate a reduction in the resulting concordance, i.e. a more successful solution. We select the most successful interventions in order to compare their values for each input parameter in the chart to the right in Fig 1. Here, each notch along one of the spokes indicates a parameter value for one of the interventions, and hence, each intervention can be composed from a set of notches on each of the spokes.
FIG 1 HERE
Beginning from “Intolerance” and working clockwise through the spokes on Fig. 1, we consider the significance of the values arrived at for each, highlighting values that contribute to disruptive solutions. Overall, these solutions cluster around medium-low intolerance levels, high obligatoriness, middling exclusiveness, high catchment areas, a wide range of neighbourhood distances, and “beachhead” venue positions.
Intolerance: The intolerance values are clustered tightly around the value of 0.4 in successfully disruptive solutions. This value, just above the traditional Shelling tipping point, can be understood as a trade-off: it is high enough to motivate some movement by individuals, but low enough to support these same agents moving to an integrated rather than segregated destination.
Obligatoriness: The obligatoriness values tend towards 1 in disruptive solutions. Since obligatoriness controls the fraction of individuals that will feel compelled to visit venues, and since venues are the mechanism for disrupting the settled state, it follows that maximizing venue attendance will maximize the potential disruption. By contrast, introducing venues that inspire no obligation to attend them will do little to alter a segregated condition.
Exclusivity: Since exclusivity controls the number of other-group individuals who will consider visiting a venue, it regulates the new encounters between the segregated groups. It follows that an exclusivity of less than 1 is necessary in order to yield any new outcomes. On the other hand, if the exclusivity is too low, any agents within the travel distance would visit and it would hence replicate the distribution of the surrounding area. Between these extremes, and in fact closer to an exclusivity range from 0.4 to 0.6, we have circumstances in which some individuals of the opposite group will be drawn into a venue, leading to a disruption when they find that after visiting they are no longer comfortable with their location. Thus maximizing disruption involves introducing venues that are neither too exclusive nor too open but rather those that exist in a “sweet spot” between the two extremes.
Neighbourhood Distance: The neighbourhood distance is the most dispersed of the non-location parameters, with all of its distribution occurring below a value of 4. We interpret this to imply that neighbourhood distance does not play a significant role in the outcome, so long as it is sufficiently low.
Venue Travel Distance: Unlike neighbourhood distance, the venue travel distance is very tightly clustered, and tends towards the highest value possible. Since venue travel distance directly determines the number of individuals who can be affected by the venues, higher values naturally yield more disruptive results. Thus introducing venues with large catchment areas is likely crucial to interventions designed to unsettle existing patterns of segregation.
Venue Positions: Each of the two venues’ positions are encoded as an X and Y value between 1 and 50. This allows them to be located anywhere in the simulation world, even if this means displacing an individual from their initial condition. While their positions in successful solutions are mostly constrained to a narrow range, the X position of the first venue is something of an exception – with a whole range of positions that yield disruptions. In Fig 2, we summarize our findings for the venues’ positions by stepping through each cell, finding any simulations in which one of the venues occupies this cell, and colouring the cell according to the most disruptive outcome from among these simulations. In other words, we colour each square according to a best-case scenario of having a venue located there. What results is a map of the most effective positions for locating venues.
FIGURE 2 HERE
Venues at “beachheads” are most likely to disrupt stable segregation patterns.Though the central map of Fig 2 clearly illustrates that there is a broad band of more successful venue locations along the boundary area between the two segregated groups, closer inspection reveals that ideal positions tend to be slightly embedded within one of the groups, rather than in the unoccupied space between. The tight clustering of values for the other parameters suggest that the successful disruptive runs are all variations on a single, emergent, strategy. This strategy involves locating a relatively open venue of a group (G1) near to the edge but slightly embedded within the segregated neighbourhood of the opposite group (G2). Because of the high maximum travel distance, individuals from the G1 are able to visit from farther away, while some closer agents from G2 are welcomed by the low exclusivity. Upon visiting, these G2 agents become less comfortable with their location, since attendance has exposed them to a greater number of agents from G1. Simultaneously, the opposite dynamic is unfolding somewhere else in the simulation world. Because of this symmetry, individuals from both groups who feel compelled to move will find new locations opening up within travel distance to an appropriate venue, leading to an exchange between two areas of the simulation world. Since the venue exclusivity is not too low, this exchange is not a complete flip – only the fraction of individuals who visit the opposite venue will relocate. These venues act like a “beachhead”, pushing away individuals from the other group and opening up spaces for their own agents to occupy. We can watch this same dynamic unfolding in the Video.
Summary
In this study, we consider the possibility of applying our venue model as an intervention in highly segregated conditions. The success of the genetic algorithm in finding highly disruptive venue configurations speaks to the potential role for planning and design as a means of re-integrating a divided urban condition. It must be stressed that the successful strategy described in this study is specifically tuned to the particular starting conditions that were used. Nonetheless, this study points at specific spatial relationships between segregated groups and disruptive venues as well as the crucial balancing of parameters such as intolerance and exclusivity. Further research would be necessary to generalize these results for other kinds of initial distributions of the simulated population.
It goes without saying that most of our lives are spent in buildings. Less obvious are the implications of this obvious fact.
Consider a two-dimensional map. It presents a smooth surface, but the reality it represents is warped. Certain points on it support more interaction than others: the ones with buildings on them. Being near such a point puts you in close contact with more people than elsewhere. Depending on the social rules governing who is supposed to be there and what they are supposed to do, the building may increase or decrease your chances of coming into contact with people similar to or different from yourself.
They are not just physical structures, they are venues for social life, and the social order of cities grow up around them. If they change — their number and distribution, their rules of social inclusion or exclusion, the types of activity they afford — the city changes as well. This combination of forms, groups, and activities is the anchor of ourmodel of urban evolution.
In a new paper (with Ultan Byrne and Patrick Adler), we show via computer simulations the power of venues to affect the broader urban order by shaping the interactions of individuals. We do so by building upon the classic work of Thomas Schelling/ In 1971, Schelling proposed what became known as the “Schelling model of segregation,” which expressed in an especially clear way the type of thinking for which he eventually received the Nobel prize: local, small-scale interactions generate larger aggregate structures, often in surprising ways.
The “Schelling model of segregation” shows this vividly. Imagine a checkerboard with red and blue pieces that represent individuals. Let’s say each individual has a desire to be around people of their own group. Let’s make it relatively small: a red individual wants at least 25-30% of the others around them to be red, otherwise the’ll move to a different location where this condition is met, if they can.
Schelling showed that, starting from a random distribution of reds and blues, if you repeat this process over and over again you’ll end up with basically total segregation of red and blue. The map that results looks eerily like real cities.
The irony is that, within the Schelling model, no individual agent wants this outcome. The social structure is not necessarily a direct result of individual intentions. Moreover, once that pattern of segregation sets in, outside of a radical transformation of human psychology, little can be done to alter it (within this model).
This is a model and like any model it makes many simplifying assumptions. In our paper, we think through the implications of something maybe so simple that prior studies of this model have largely overlooked: there are no buildings in it, it does not capture the warped space we live in.
So we built a model that extends Schelling’s to include buildings in the simplest way we could think of. Basically, you need four things: 1. a travel radius (how far your reds and blues will go to visit the venue); 2. exclusivity (is the venue exclusive to one group, like an exclusive golf club, or is it open to members of any group); 3. obligatoriness (are individuals obliged to attend it, like an orthodox synagogue, or is it more optional, like a cafe); 4. physical features (how many venues are there, and where are they located).
With those simple features, you can account for, and observe the logical implications for urban segregation and integration, of one of the most pervasive facts of our experience, which is that we congregate in buildings. This happens because the people you interact with in buildings alter the Schelling-style calculation as to whether an individual feels “comfortable” in their location. One might be a majority in terms of the people who live nearby or who you pass by on the street, but a minority when you include those you meet in the venues. Or vice versa: you might be a minority in terms of who lives there, but interact with many people of your group in the local venues (who traveled there from elsewhere) or travel elsewhere to interact with members of your group.
By repeating and varying those simple processes you can think through their implications. One is that they generate a distinctively urban order: Schelling’s model yields clumps whose physical location has no meaning or basis. With buildings in the model, you can generate an East vs. West side (“opposite sides of the tracks”) or a centre-periphery structure with a more diverse core and more homogenous peripheries.
You can also observe how, depending on the characteristics and location of the building, it is possible to forestall the deep segregation characteristic of the Schelling model from arising, without requiring any radical transformation of individuals’ psychology. You can also unsettle deeply sedimented patterns of segregation through the right combination of venue parameters, whereas they are basically set in stone in Schelling’s highly individualistic model (via a genetic algorithm, not shown in this paper but coming to a blog post soon)
And you can find ironies and reversals like the sort Schelling exposed. Just as Schelling demonstrated that one cannot simply read individual intentions from collective patterns of behavior, one cannot simply read organizational values from their surrounding patterns of segregation. Relatively exclusive venues can generate diverse neighborhoods (by providing a local foothold for minority groups to sustain their distinctive cultures), while relatively inclusive venues can in some circumstances produce highly segregated areas (by drawing in tolerant and “adventurous” persons who, despite their individual understanding, change the overall makeup of the area).
An advantage of the computer simulation approach is that you can pinpoint the precise mechanisms by which these outcomes occur. Some of these include “evacuation,” “cooptation,” “bootstrapping,” “cascading,” and “bridging.”
The paper also includes videos showing the simulation runs unfold.
The abstract is below. The paper is freely available here.
Abstract: This paper examines an important but underappreciated mechanism affecting urban segregation and integration: urban venues. The venue- an area where urbanites interact- is an essential aspect of city life that tends to influence residential location. We study the venue/segregation relationship by overlaying venues onto Schelling’s classic (1971) agent-based segregation model. We show that a simulation world with venues makes segregation less likely among relatively tolerant agents and more likely among the intolerant. We also show that multiple venues can create spatial structures beyond their catchment areas and that the initial location of venues shapes later residential patterns. Finally, we demonstrate that the social rules governing venue participation alter their impacts on segregation. In the course of our study, we compile techniques for advancing Schelling-style studies of urban environments and catalogue a set of mechanisms that operate in this environment.
In the the second instalment of this year’s seminar series, we continued to host a dialogue about the adaptation of evolutionary thinking to the study of cities. We were delighted to host Juste Raimbault, from University College London.
Dr. Raimbault is the author of a stream of veryinteresting work on theories and models of urban evolution, coupled with epistemological insights about the value and meaning of interdisciplinarity. This work informs own theorizing in Parts I, II, and III of “Towards a Model of Urban Evolution” — which thanks to Dr. Raimbault’s critical commentary we will continue to revise under the more appropriate heading, “Towards a meta-model of urban evolution.”
For our seminar, Dr. Raimbault presented his paper on “Modelling urban evolution and co-evolution in systems of cities.? The abstract is below, and a recording of the presentation may be viewed here.
Systems of cities are adaptive complex systems, which have been theorized and modelled from many viewpoints and by different disciplines. Understanding the processes driving their dynamics is a crucial challenge for sustainable urban and territorial planning. The concept of urban evolution has proved relevant in this regard. This presentation summarises recent results obtained within the frame of the Evolutionary Urban Theory, a geographical approach to urban systems dynamics developed for more than 20 years by Denise Pumain and collaborators. We first review the main theoretical assumptions underlying this theory and results obtained with different simulation models in previous works. We also highlight the role of new model exploration and validation practices and tools developed in that context, implemented in the OpenMOLE platform.
We then describe a model of urban evolution positioned in this approach, in which the diffusion of innovations between cities captures transformation processes (mutations) and transmission processes (diffusion), using two coupled spatial interaction models. Explorations of the model on synthetic systems of cities show the role of spatial interaction and innovation diffusion ranges on measures of diversity and utility, and the existence of intermediate interaction ranges yielding an optimal utility. Multi-objective optimization shows how the model produces a compromise between utility and diversity.
The last part of the presentation focuses on the concept of co-evolution in urban systems, proposing a specific definition, a method to characterize it based on circular causations, and an application to the co-evolution between transportation networks and territories. For this particular case, we summarise results from co-evolution models at the mesoscopic scale (co-evolution between urban form and road networks) and at the macroscopic scale (co-evolution between cities and urban networks). We finally discuss perspectives towards more complex and multi-scalar models of urban evolution.
A challenging part of developing evolutionary models of cities is their dynamism. We must find ways to treat change rather than static states as our topic of interest. That is, we often want to understand what something is by how it becomes. Two neighbourhoods might be very similar in terms of their characteristics right now, but have very different propensities to change. Likewise, two neighbourhoods might be quite different at the present moment, but change in similar ways. However, standard methods have a hard time identifying these sorts of similarities grounded in shared propensities to change in response to varying conditions.
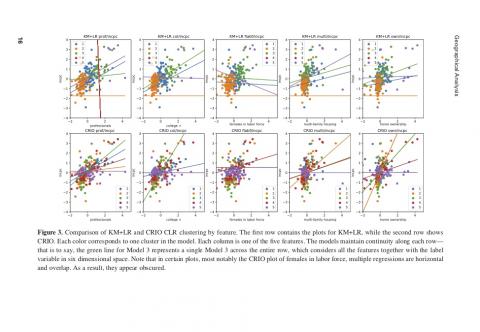
• Conceptually, predictive clustering is highly distinct from traditional methods—in particu-lar, LR. Because it relies on a predictive model, it can uncover how specific characteristics influence an outcome researchers are interested in studying. We can then observe heteroge-neity in those influences and use it to cluster observations. This perspective makes neigh-borhood dynamics fundamental to the definition of urban space.
• Methodologically, in contrast to traditional neighborhood classifications, predictive cluster-ing is based on a specific outcome to which areas similarly “respond.” In other words, our proposal can be considered model-based clustering (Fraley and Raftery 2002). This frame-work defines the current state of a neighborhood as a set of variables thought to influence trajectories of change. In this article, following a long tradition of research, we use income change to illustrate the potential of this methodological feature of our approach (for a recent example, see Hochstenbach and Van Gent 2015).
• Practically, predictive clustering has clear implications that differentiate it from the tradi-tional K-Means approach. Our approach can identify neighborhoods that exhibit different processes of change even if they look similar at any given point in time, and similar dynam-ics even when they look different. Not only is this potentially useful for urban policymakers when designing interventions, it cannot be readily examined when one only considers char-acteristics of the neighborhood, as in the traditional K-Means approach.
Below is the abstract, and here is a link to the paper.
Abstract:
This article applies a method we term “predictive clustering” to cluster neighborhoods. Much of the literature in this direction is based on groupings built using intrinsic characteristics of each observation. Our approach departs from this framework by delineating clusters based on how the neighborhood’s features respond to a particular outcome of interest (e.g., income change). To do so, we leverage a classification and regression via integer optimization (CRIO) method that groups neighborhoods according to their predictive characteristics and consistently outperforms traditional clustering methods along several metrics. The CRIO methodology contributes a novel methodological and conceptual capability to the literature on neighborhood dynamics that can provide useful insights for policymaking.